

Introduction
Some of the LLM settings allow us to manipulate the characteristics of the model, such as how 'random' it is. These manipulations are useful for users as they allow users to interact with the model according to their specific needs. You can change these parameters to get more imaginative, varied, correct, and captivating results. We go over each variable that you may alter in the OpenAI Playground, but among the most crucial ones are the Temperature, Frequency Penality, Presence Penality, Top P, and Max Length parameters.
What is Model Setting in LLM?
Let's define Model Settings before we explore its power. Model setting is the process of fine-tuning our Language Model by adjusting several parameters to maximize its performance. One can not emphasise the importance of model setting. It's the key ingredient that elevates an OK model to a remarkable one . Model setting involves carefully adjusting hyperparameters such as learning rate, batch size, and number of layers to achieve the best results. It requires a deep understanding of the model architecture and the specific task at hand. Without a proper model setting, the full potential of the language model cannot be realized.
Techniques for Key Optimisation
Now that we have the necessary equipment, let's get started with the key optimization techniques. The power of the designers shaping the Language Model's features is these optimization techniques.
Frequency Penalty
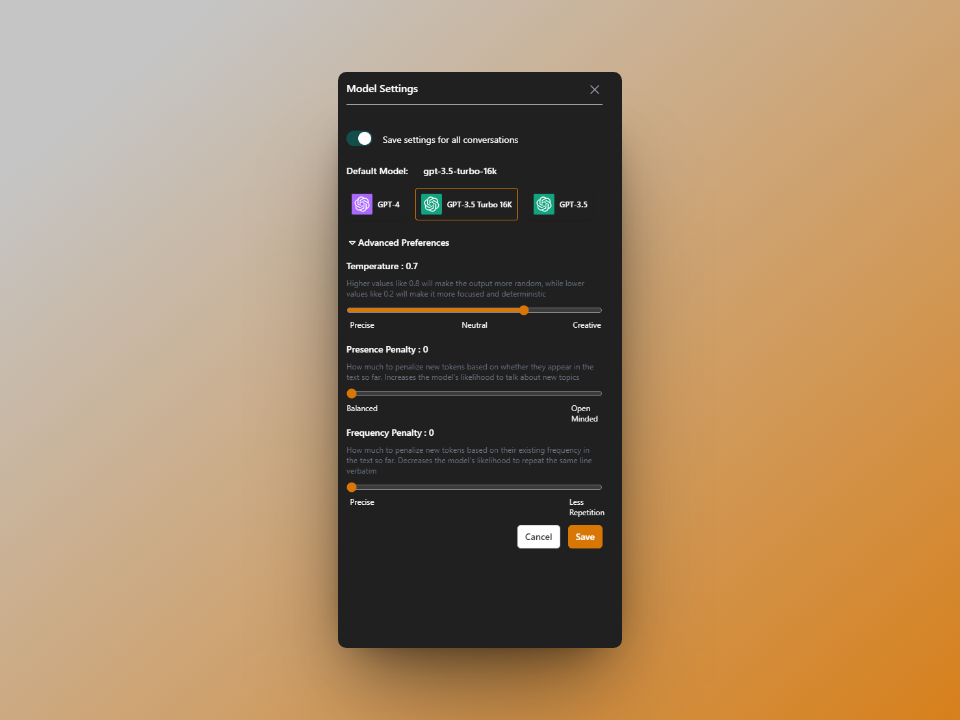
It avoids the repetition of words. Consider a friend who constantly tells the same joke. Not enjoyable, is it? By preventing repetition from boring users, Frequency Penalty ensures that the material is interesting and varied. Just like in GenExpert, you have this feature to avoid the frequency of the same words and enjoy new words and the best sentence structure.
Presence Penalty
It preserves equilibrium in outputs. Similar to a stimulating dialogue, Presence Penalty makes sure that no phrase takes the spotlight. It prevents the output from becoming overly focused on just one term. Example is shown above in GenExpert tool.
Temperature
It incorporates chance for a number of outcomes. Consider temperature as the seasoning in your food. It increases the output's randomness, which gives it more energy. Adjusting to perfection guarantees the best results for your language model. Adding just the right amount of temperature, or randomness, to your language model is like adding the perfect amount of seasoning to your food. It brings out the best flavors and ensures a more dynamic and engaging output. Just as a chef adjusts the seasoning to perfection, so you too must fine-tune your language model to achieve the best results. An example is GenExpert's temperature feature which gives you the number of outputs.
High-k Sampling
It limits the diversity of content that is generated. Your content is kept diversified by choosing tokens from the top k most likely. It's similar like selecting the finest components for a tasty meal. This approach ensures that the generated content remains coherent and relevant, providing a more focused and high-quality result. By prioritizing the top k most likely tokens, the model can produce more accurate and contextually appropriate output. This can be especially useful in tasks that require specificity and precision, such as language generation for professional or technical purposes. Overall, high-k sampling offers a valuable method for controlling the diversity and quality of generated content.
Example
Let's take an example of high-k sampling. Imagine we're continuing a story and need the next word in the sentence: "Lost in the enchanted forest, the adventurer encountered a mystical ____."
The language model considers various possibilities, each with its own probability:
- Castle (probability 0.35)
- Creature (probability 0.25)
- River (probability 0.15)
- Artifact (probability 0.1)
- Spell (probability 0.08)
- Map (probability 0.05)
- Song (probability 0.02)
Now, with high-k sampling, we set k to 4. This means the model will consider the top 4 most likely tokens. Let's see how it works:
- Considering Castle, Creature, River, and Artifact (total probability 0.85).
With high-k sampling, the model randomly selects one of these top 4 options. In this case, let's say it picks Creature.
High-k sampling allows for a controlled level of randomness by considering a subset of the most likely tokens.
Nucleus Sampling, or Top-p Sampling
Using Top-p Sampling, you may dynamically modify the "p" parameter to manage the unpredictability in the output of your language model, much like a chef modifying a recipe. By adjusting the "p" parameter, you can control the level of diversity in the generated text, allowing you to tailor the output to better suit your needs. Just like a chef tweaking the ingredients in a dish, you can fine-tune the sampling process to achieve the desired balance of creativity and coherence in the generated language model output.
Example
Let's dive into an example to understand how Top P works. Imagine we're completing the sentence: "On a sunny day, I like to take my ____ for a walk." The model is trying to predict the next word, and it's considering a few options:
- Dog (probability 0.6)
- Bike (probability 0.2)
- Book (probability 0.1)
- Camera (probability 0.05)
- Friend (probability 0.03)
Now, let's say we set Top P to 0.80. The AI will focus on the tokens that, when added up, reach at least 80%. So, it goes like this:
- Adding Dog -> total so far is 60%.
- Adding Bike -> total becomes 80%.
At this point, the cumulative probability is 80%, so the AI stops considering other options. When generating output, the AI will randomly choose between a Dog and a Bike since they make up around 80% of all likelihoods.
This way, Top P helps narrow down choices based on cumulative probabilities, making the generated content more focused and controlled. It's like having a smart assistant that knows to pick from the most likely options, giving you a result that's both diverse and relevant to the context.
Beam Investigation
It helps in finding a balance between exploration and exploitation. Beam Search leads your model through a series of steps. It balances exploration and exploitation in sequence generation by choosing the best sequences at each stage. Beam search is a popular algorithm used in natural language processing and other fields to generate sequences of words or actions. It works by keeping track of a fixed number of candidate sequences at each step and then choosing the best ones to continue exploring. This helps to ensure that the algorithm explores a wide range of possibilities while also focusing on the most promising options. Overall, beam search is a powerful tool for balancing exploration and exploitation in sequence generation.
Various Beam Search
It improves diversity in the search. Diverse Beam Search gives your language model the same diversity as a varied menu. It reduces redundancy in produced sequences and increases diversity. Incorporating these sampling techniques into your language model can greatly enhance the quality and diversity of the generated content. By carefully selecting tokens, dynamically adjusting parameters, and balancing exploration and exploitation, you can ensure that your model produces varied and engaging output. Whether you're aiming for a diverse menu of options or a finely tuned recipe, these sampling methods offer a range of tools to improve the performance of your language model.
Learning Rate Schedulers
Dynamic adjustment for fine-tuning: Learning Rate Schedulers enhance convergence and fine-tuning by dynamically adjusting learning rates during training, much like a guitar tuner would. This allows for more precise and efficient training, leading to better performance and generalization of the model. Learning Rate Schedulers can help prevent overfitting and improve the overall stability of the training process.
Weight Tying
The minimalist technique is Weight Tying, which lowers parameters and increases efficiency. Distributing weights among various model components lowers parameters and boosts effectiveness. Weight Tying is a powerful tool in reducing the complexity of machine learning models. Sharing weights across different parts of the model, not only simplifies the structure but also improves generalization and reduces the risk of overfitting. This technique has been widely adopted in various deep-learning architectures and has proven to be highly effective in achieving better performance with fewer parameters.
Difficulties in Model Setting
There are obstacles on every journey. Let's overcome the obstacles:
Balancing Penalties
It's an art to strike a balance between penalties. Finding the ideal balance guarantees that the outputs your language model produces meet user expectations.
Handling Uncertainty and Ambiguity
Ambiguity is a common companion in the domain of language models. To ensure that outputs stay consistent, strategies for handling uncertainties with grace must be in place. Navigating through the complexities of model setting requires careful consideration and strategic planning. It's essential to address these challenges head-on and implement effective solutions to ensure the success of your language model.
Strategies For Effective Model Setting
Here are some of the techniques to overcome these obstacles:
Iterative Optimization
- Setting up a model is a continuous process. By using iterative optimization, you can be sure that your language model will adapt to changing job requirements and user needs. Adapting to New Data
Language is constantly evolving, and so should your model. It's crucial to have techniques in place for incorporating new data and updating your model accordingly. User Feedback Integration
- Listening to user feedback is essential for improving your language model. By integrating user input into your model development process, you can ensure that it continues to meet the needs and expectations of its users.
Robust Evaluation Methods
- Developing effective evaluation methods is key to ensuring the quality and performance of your language model. By implementing robust evaluation techniques, you can accurately assess the strengths and weaknesses of your model and make necessary improvements.
The Human Touch in Model Setting
Let's infuse the mixture with some humanity:
Combining Creativity and Intuition
- Your language model is an extension of your imagination, not merely a tool. Adding imagination and intuition to your work gives it a more human touch.
Adding Character to the Model
- It takes more than just coming up with words; you also need to develop a personality. Adding a personality to your model guarantees that the results are exclusively yours.
Injecting emotion into the model
- Don't be afraid to inject emotion into your model. Emotion is what makes us human, and infusing your language model with emotion can make it more relatable and engaging for your audience.
Building Empathy into the Model
- Empathy is a key component of human interaction, and it should also be a part of your language model. By incorporating empathy into your model, you can ensure that it understands and responds to the emotions and needs of its users.
Creating a Connection with the Audience
- Ultimately, the goal of infusing humanity into your model is to create a connection with your audience. By making your model more human-like, you can build trust and connection with the people who interact with it.
Conclusion
The skill of establishing them in the wide world of language models involves a careful balancing of methods. The objective is to produce outputs that are not only accurate but also rich in context and captivating, whether that involves adjusting penalties or experimenting with temperature. The process requires a deep understanding of the nuances of language and a keen eye for detail. It also involves continuous learning and adaptation to stay ahead of the curve in this rapidly evolving field. By honing these skills, language models can continue to push the boundaries of what is possible and deliver increasingly impressive results.
FAQs
How does Frequency Penalty enhance content quality?
- Frequency Penalty adds variety to content by preventing word repetition, making it more engaging for readers.
How does Weight Tying contribute to model efficiency?
- Weight Tying reduces parameters by sharing weights between different parts of the model, improving efficiency.
Why is Continuous Monitoring and Adaptation crucial in model optimization?
- Continuous Monitoring and Adaptation ensure that the model evolves to meet changing user needs and task requirements, staying relevant in a dynamic landscape.